Impressum ISSN 1867-7991 | ||
| freiesMagazin erscheint als PDF und HTML einmal monatlich. | ||
| Redaktionsschluss für die Juli-Ausgabe: 23. Juni 2010 | ||
| Kontakt | ||
| Postanschrift | freiesMagazin | |
| c/o Dominik Wagenführ | ||
| Beethovenstr. 9/1 | ||
| 71277 Rutesheim | ||
| Webpräsenz | http://www.freiesmagazin.de | |
| Autoren dieser Ausgabe | ||
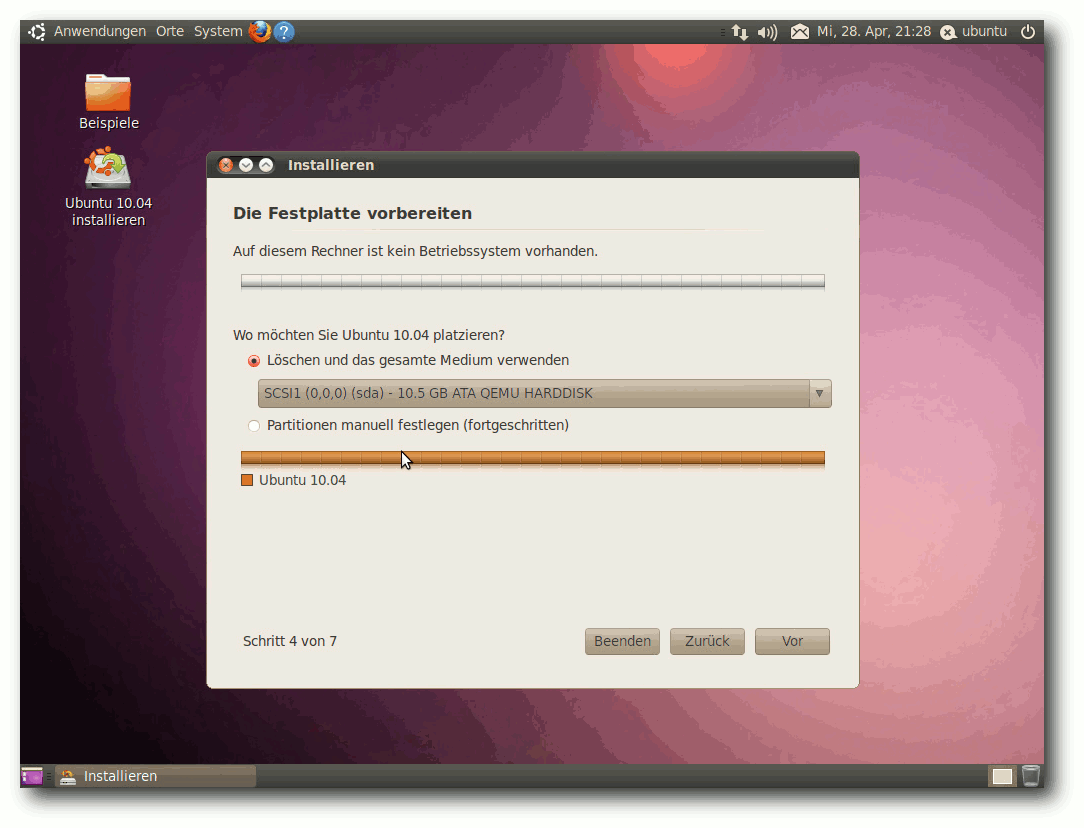
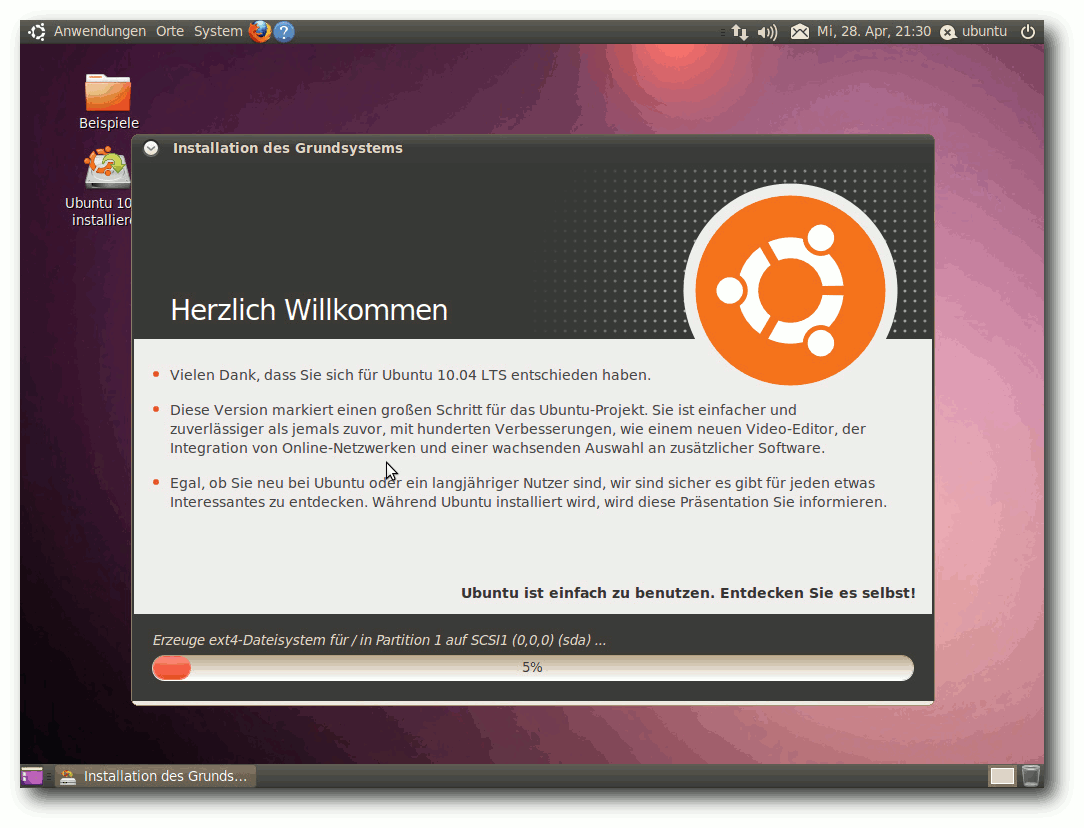
| Hans-Joachim Baader | Ubuntu 10.04 | |
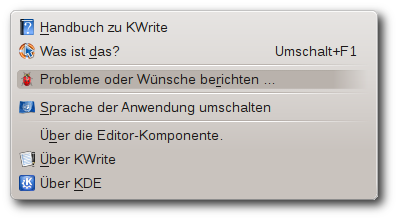
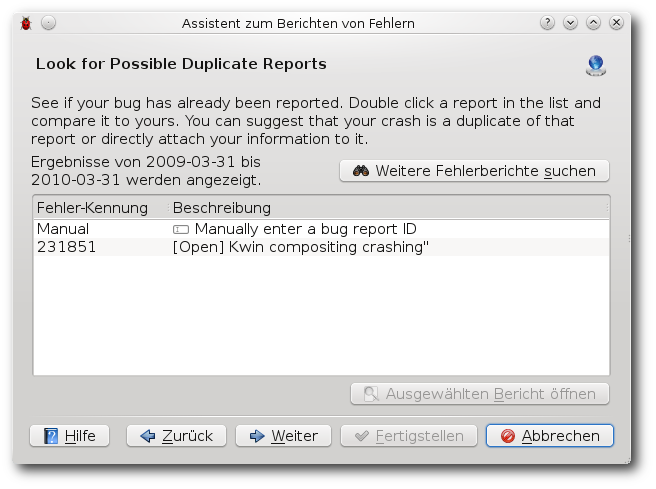
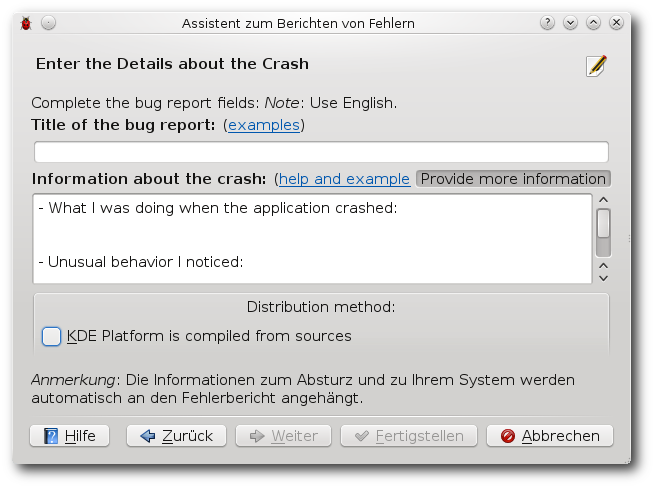
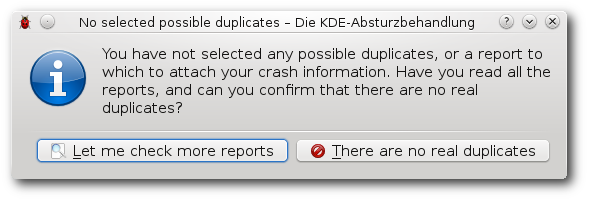
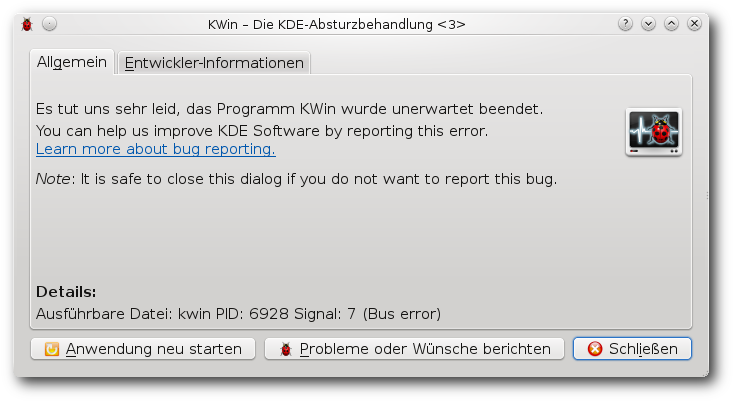
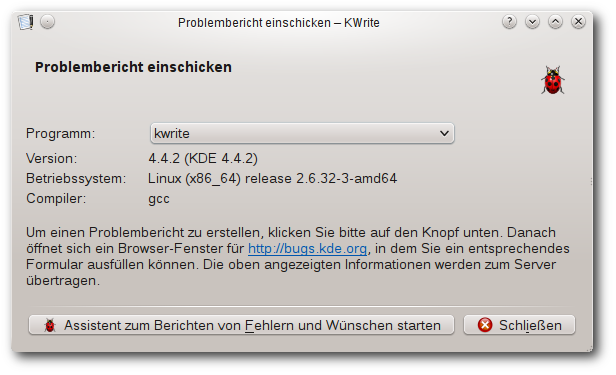
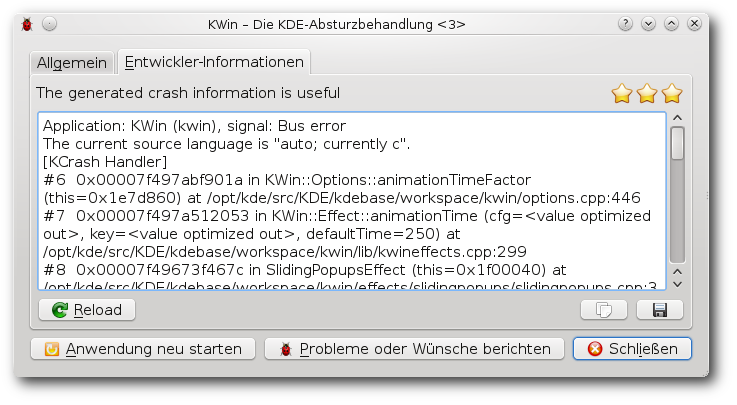
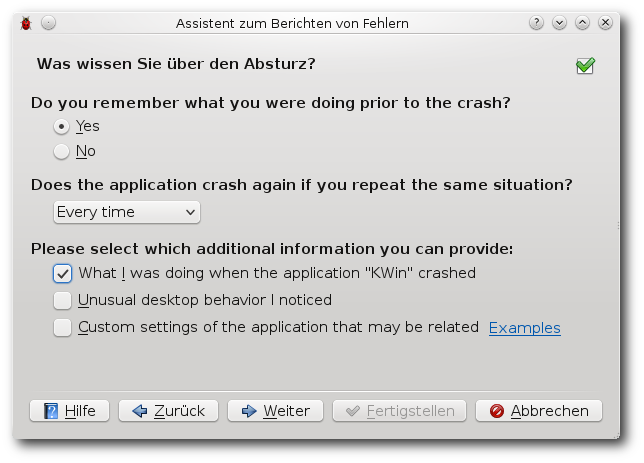
| Martin Gräßlin | Käferalarm! – Was tun bei Bugs? | |
| Roman Hanhart | Das Grmlmonster und seine Zähne | |
| Mathias Menzer | Der Mai im Kernelrückblick | |
| Jürgen Mischke | Rezension: Typo 3 – Das Praxishandbuch für Entwickler | |
| Kirsten Roschanski | Welches Betriebssystem ist das richtige für Netbooks? | |
| Bodo Schmitz | Verschlüsselt installieren | |
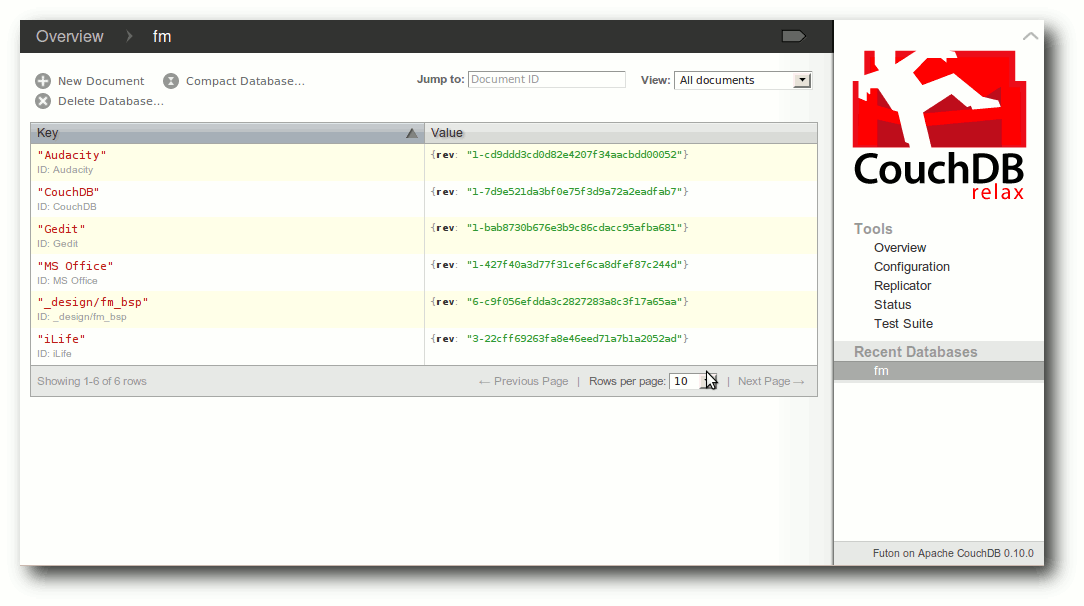
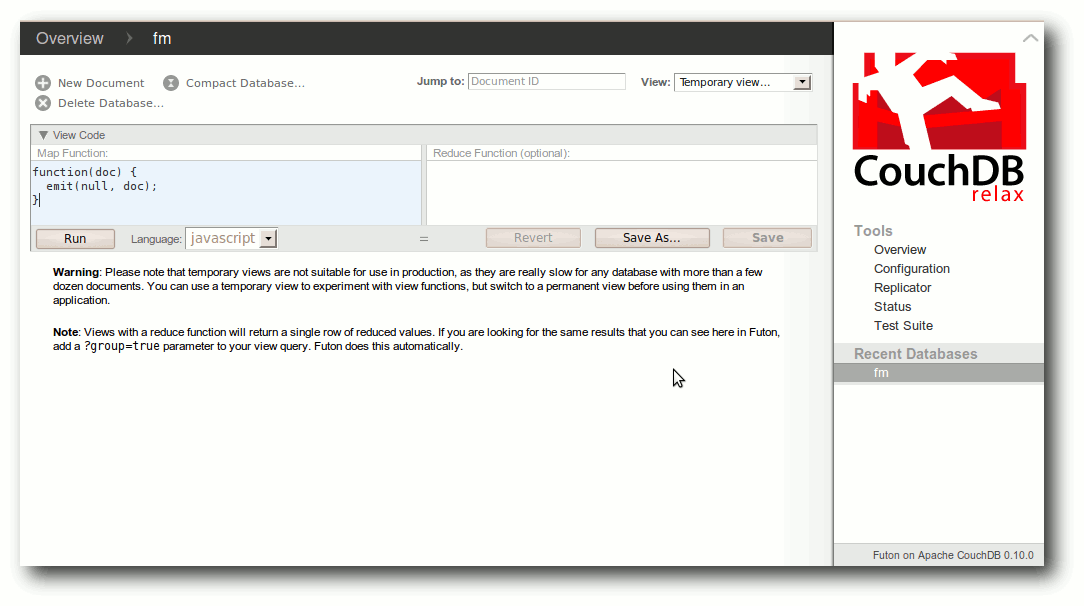
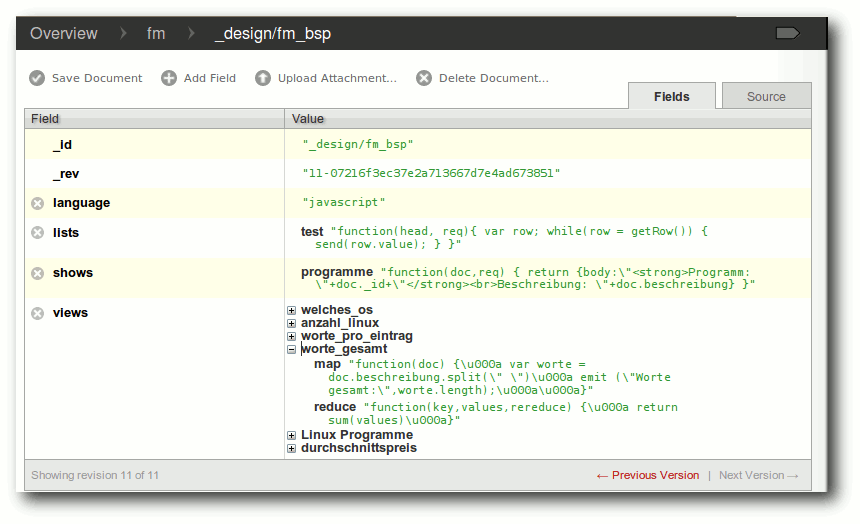
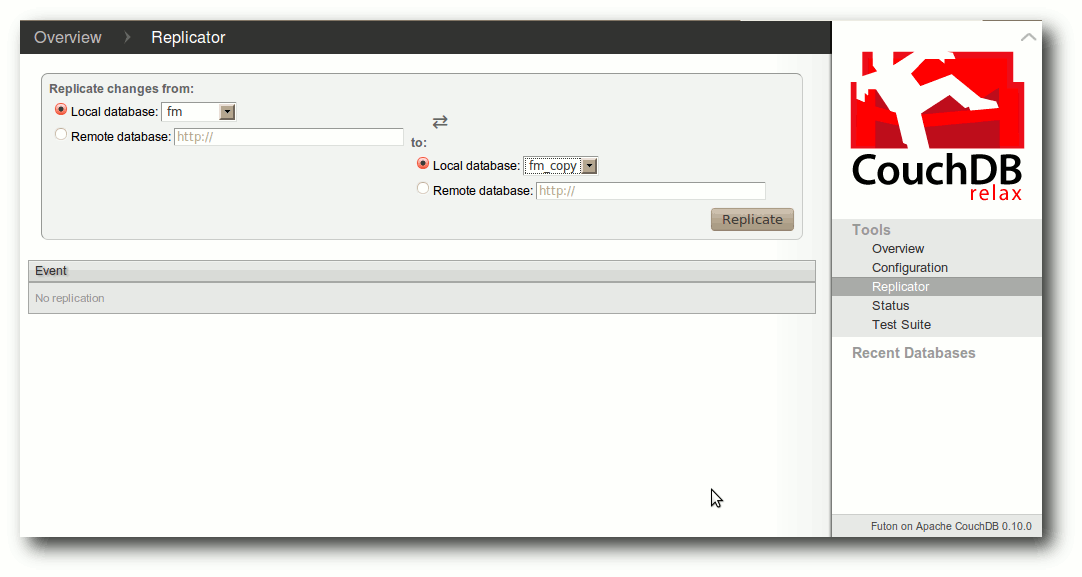
| Jochen Schnelle | CouchDB – Datenbank mal anders | |
| Joachim Seemer | Haiku - eine Altnerative für den Desktop | |
| Dominik Wagenführ | Kurztipp: Unicode-Zeichen in LaTeX nutzen | |
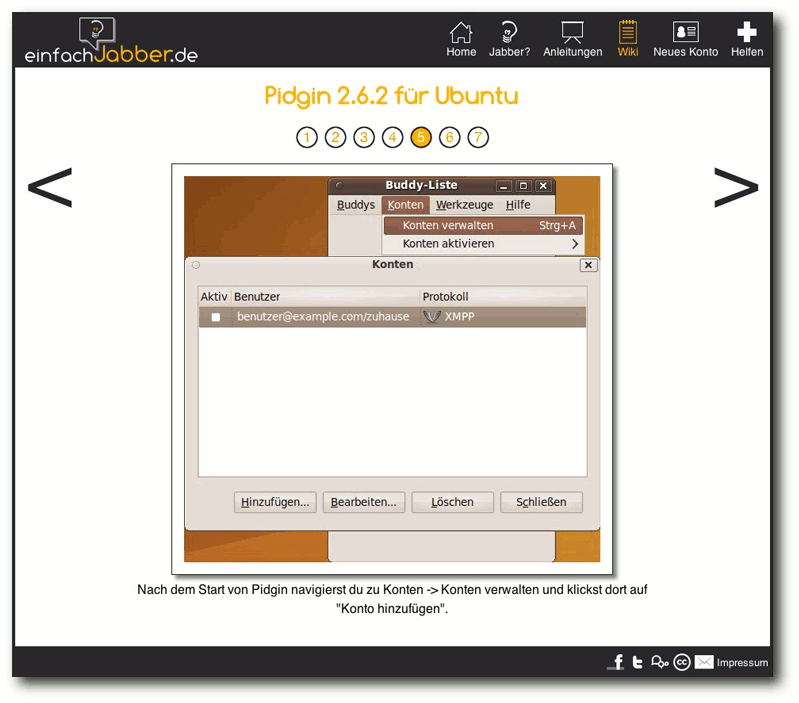
| Benjamin Zimmer | Projektvorstellung: einfachJabber.de | |
| Erscheinungsdatum: 6. Juni 2010 | ||
| Redaktion | ||
| Dominik Honnef | Thorsten Schmidt | |
| Dominik Wagenführ (Verantwortlicher Redakteur) | ||
| Satz und Layout | ||
| Ralf Damaschke | Yannic Haupenthal | |
| Sebastian Schlatow | ||
| Korrektur | ||
| Daniel Braun | Frank Brungräber | |
| Stefan Fangmeier | Mathias Menzer | |
| Karsten Schuldt | Franz Seidl | |
| Stephan Walter | ||
| Veranstaltungen | ||
| Ronny Fischer | ||
| Logo-Design | ||
| Arne Weinberg (GNU FDL) | ||
Soweit nicht anders angegeben, stehen alle Artikel und Beiträge in freiesMagazin unter der GNU-Lizenz für freie Dokumentation (FDL). Das Copyright liegt beim jeweiligen Autor. freiesMagazin unterliegt als Gesamtwerk ebenso der GNU-Lizenz für freie Dokumentation (FDL) mit Ausnahme von Beiträgen, die unter einer anderen Lizenz hierin veröffentlicht werden. Das Copyright liegt bei Dominik Wagenführ. Es wird die Erlaubnis gewährt, das Werk/die Werke (ohne unveränderliche Abschnitte, ohne vordere und ohne hintere Umschlagtexte) unter den Bestimmungen der GNU Free Documentation License, Version 1.2 oder jeder späteren Version, veröffentlicht von der Free Software Foundation, zu kopieren, zu verteilen und/oder zu modifizieren. Die xkcd-Comics stehen separat unter der Creative-Commons-Lizenz CC-BY-NC 2.5. Das Copyright liegt bei Randall Munroe.
Zum Index